
This is a response to an article by philosopher Michael Huemer on AI risk, and why he believes the most dire concerns are unwarranted. I stand by my endorsement of Huemer's work in other fields, but I believe he's wrong on this subject. I hope to show why.
In the comments of a facebook post made on 18 february 2023, about doomsday cults, Huemer answers a question about AI risk by linking to his 2020 post Existential Risks: AI. Huemer's reference to this article suggests that at the time of writing he believes the arguments presented therein are sufficient to dispel concerns about the possibility of catastrophe for human kind caused by (autonomous) artificial intelligence.
The motivation of an AI
Huemer writes:
the way that most people imagine AI posing a threat -- like in science fiction stories that have human-robot wars -- is anthropomorphic and not realistic. People imagine robots that are motivated like humans -- e.g., megalomaniacal robots that want to take over the world. Or they imagine robots being afraid of humans and attacking out of fear.
Advanced AI won't have human-like motivations at all -- unless we for some reason program it to be so.
I don't know why we would program an AI to act like a megalomaniac, so I don't think that will happen.
Computers will follow the algorithm that we program into them.
The important mistake here is assuming that creating an AI is a similar process to traditional software engineering; Where humans write explicit instructions telling the program how to behave any point during runtime. If the program ends up behaving unexpectedly it's because a human has made a mistake that can be fixed through debugging.
But software based on Large Language Models (ChatGPT, Bing), and presumably more powerful things that might get called AIs, are chiefly the product of machine learning with neural networks, not traditional software development.
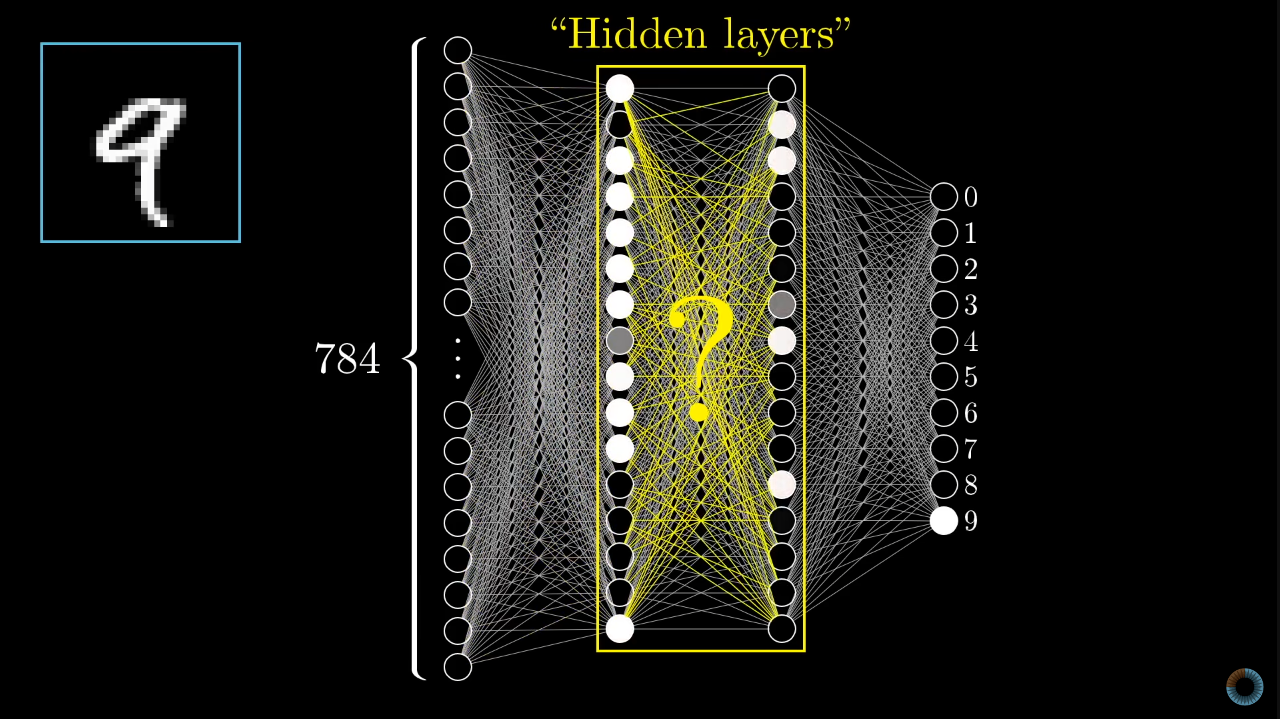
A neural network consists of layers of interconnected nodes, neurons, that are capable of processing and transmitting information. When a neural network is trained, it's fed a lot of data and its outputs are scored against some criteria. During this process the weights of the connections between neurons are programatically altered by a simple algorithm which iteratively nudges the network towards giving higher scoring outputs–being better at what we intend it to do.
gradient descent is an optimization algorithm that searches over the space of neural net parameters to find a set that performs well on some objective.
AN #58 Mesa optimization: what it is, and why we should care
Unlike a traditional computer program that's amenable to debugging, a trained neural network is effectively a black box; an inscrutible set of nodes with connections of different weights–float numbers–between them. We can look at an inputs and compare it against the output, but as humans we can't understand what the network is doing by looking at the topology and the numbers.
When the goal of training is small and well defined, like having a neural network reliably recognise hand-written numbers, this is fine. We can easily tell whether or not the network is working as we hope, and there's no possibility of disaster. But in the case of a future general intelligence, which can take autonomous action in the world, where we might try to train to the directive "don't covertly have goals that most humans would object to", that's much harder.
This isn't only a theoretical concern. Alignment problems have been demonstrated in simple video game models. For instance, subtle statistical differences between the training environment and the 'deployment' environment revealed that a model had adopted a misaligned goal, that worked well in training but gave unwanted (at least to its makers) results afterwards.
Update. I misunderstood Huemer in this section. Where he uses the verb 'program' he intends it more broadly that I assumed, to include the process of training a neural network. But I'll leave the above section unedited in case it's useful for others. Huemer replies:
Re: "The motivation of an AI": What I had in mind was that the programmers wouldn't train the AI for megalomaniacal behavior; anything like that in the training period would be labelled "bad". We know why humans (esp. men) have that behavior, but nothing like that explanation would apply to AI.
This doesn't rule out that some crazy behavior might emerge in novel circumstances. It's just unlikely to be crazy in the way crazy humans are crazy. It's more likely to be something that makes no sense to us. Or so I would guess.
Mesa optimisers
There's no guarantee that when you use gradient descent to optimise for a particular thing, that the general intelligence that you eventually get also wants that same thing.
I am a mesa-optimizer relative to evolution. Evolution, in the process of optimizing my fitness, created a second optimizer - my brain - which is optimizing for things like food and sex.
Deceptively Aligned Mesa-Optimizers: It's Not Funny If I Have To Explain It
The material on (deceptively aligned) mesa-optimisers in AI is particularly interesting here. I won't repeat more of it here but I recommend taking a look.
As Eliezer Yudkowsky puts it nobody has the technical knowledge to control, in detail, what a powerful AGI ends up caring about. In a situation that couldn't arise in traditional softwared engineering, our ability to create (proto) AI's outstrips our ability to reliably instill in them with human-like ideas about acceptable behaviour, and the prospects for changing that state of affairs don't look good.
you run myopic gradient descent to create a strawberry picker. It creates a mesa-optimizer with some kind of proxy goal which corresponds very well to strawberry picking in the training optimization, like flinging red things at lights [the light reflecting off the bottom of the metal bucket]
"While speculating about the far future, it realizes that failing to pick strawberries correctly now will thwart its goal of throwing red things at light sources later. It picks strawberries correctly in the training distribution, and then, when training is over and nobody is watching, throws strawberries at streetlights.
(Then it realizes it could throw lots more red things at light sources if it was more powerful, achieves superintelligence somehow, and converts the mass of the Earth into red things it can throw at the sun. The end.)"
Deceptively Aligned Mesa-Optimizers: It's Not Funny If I Have To Explain It
Megalomania and instrumental convergeance
Huemer writes:
The desire to take over the world is a peculiarly human obsession. Even more specifically, it is a peculiarly male human obsession. Pretty much 100% of people who have tried to take over the world have been men. The reason for this lies in evolutionary psychology (social power led to greater mating opportunities for males, in our evolutionary past). AI won't be subject to these evolutionary, biological imperatives.
Instrumental convergence is a concept in artificial intelligence that suggests that as an AI becomes more intelligent and capable, its goals and motivations are likely to include a certain set of objectives, regardless of its primary goal.
For instance, an AI might notice that in order to optimally achieve it's goal it's important not to be interrupted by being turned off, so it would be good if it could eliminate the risk of that from happening. And it might notice that the more of the universes resources it can control, the more effective it will be at pursuing it's primary value. Both of these things will tend to create megalomania.
I hope I've satisfactorily indicated how it's reasonable to consider future AGI a real threat to humanity in itself, even before it gets into the hands of people who are evil or negligent.
Read more? All articles
I create videos with the help of my patrons great and small.
Find out more about supporting my work.
Would you like to get emails now and then when I publish new things? Leave your address here.